


產品特色
- 5120 NVIDIA®CUDA®平行運算處理核心
- 32GB HBM2 記憶體容量
- 最高至 870GB/s記憶體頻寬
- 7.4 TFLOPS FP64 效能
- 14.8 TFLOPS FP32 效能
- 29.6 TFLOPS FP16 效能
- 59.3 TOPS INT8 效能
- 118.5 TFLOPS Tensor 運算效能
- 4x 4096x2160 @ 120Hz 顯示解析度
- 2x 7680x4320 @ 60Hz 顯示解析度
- 最大功耗 250W
效能與特性
Volta GPU 架構
Quadro GV100 基於NVIDIA制定的最先進12奈米FFN(FinFET NVIDIA)高性能製程技術, 其集成了5120 CUDA內核,是專業人士用於HPC,AI,VR和圖形工作的最強大的計算平台桌面。
Tensor 核心
Quadro GV100使用640個Tensor 運算核心; 新一代混合精密內核專用於深度學習矩陣算法,與前一代相比,可提供8倍兆次的浮點運算之訓練效能。
高速 HBM2 記憶體
以業界最快的圖形記憶體為基礎,搭載Volta極為優化的32GB HBM2記憶體,Quadro GV100更是適用於處理大型數據集的延遲敏感應用的理想平台。 與上一代相比,Quadro GV100提供兩倍的記憶體容量並提供20%以上的記憶體頻寬。
混合精準度計算
透過16位浮點精度計算,使吞吐量加倍外並降低存儲需求,從而支持大型神經網絡的訓練和部署。 通過獨立平行整數和浮點數據路徑,Volta SM在計算和尋址計算混合的工作負載上也更加高效。
H.264 與 HEVC 編解碼引擎
通過兩個專用的H.264和HEVC編碼引擎以及獨立於3D/計算管道的專用解碼引擎,為轉碼,視訊編輯和其他編碼應用,提供比即時性能更快的高效表現。

多 GPU 技術
第二代 NVIDIA® NVLink
使用NVLink連接兩片Quadro GV100卡,以增加有效記憶體佔用量並擴展應用程序性能,來達到GPU與GPU之間的數據傳輸以高達雙向100GB/s,200 GB/s總頻寬的速率效能。
NVIDIA® SLI® 技術
利用多個GPU來動態縮放圖形性能,增強圖像品質,擴大顯示空間,並組合完整虛擬化的系統。
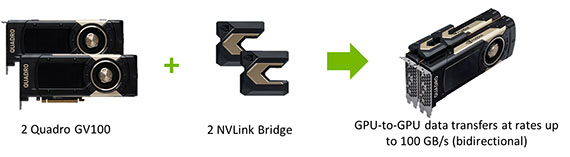
NVIDIA的NVLink技術提供兩塊GV100卡之間的高速連接與結合成一個HBM2 64GB記憶體。
這使得兩個GPU都能夠處理最大的計算工作量,為單一個工作站提供最佳的視覺處理計算解決方案。
影像品質

全景抗鋸齒(FSAA)
顯著地降低了視覺混疊偽影或“鋸齒”,具有高達64倍FSAA(使用SLI更可達到128倍),實現無與倫比的圖像品質和高度逼真的場景。
32K材質和渲染處理
材質渲染到32K x 32K表面,以支持那些需要最高解析度和高品質圖像處理的應用。
記憶體壓縮
使用第四代無耗損增量壓縮技術,通過減少每幀記憶體中獲取的數據量,並將將頻寬提高多達20%。
專業顯示功能
高速DisplayPort 1.4
支援多達四個5K 60Hz顯示器或每張卡雙8K顯示器。 Quadro GV100支持4K 60Hz的HDR彩色,用於10/12b HEVC解碼,高達4K 60Hz用於10b HEVC編碼。 每個DisplayPort連接器都能夠以30位色彩驅動4096x2160 120 Hz的超高解析度。
NVIDIA® nView® 進階桌面管理軟體
獲得前所未有的最終用戶對桌面管理的體驗,以提高單一大型顯示或多顯示器環境的生產力。
NVIDIA® Quadro® Mosaic 技術
從單一工作站跨多達4個GPU和16台顯示器,無障礙地擴展桌面和應用軟體,同時提供全面的性能和影像質量,並針對靜態圖像可視化和統一桌面進行優化。

NVIDIA® Quadro Sync II
在單一系統中同步來自8個GPU(通過兩個Sync II板卡連接)的多達32個顯示和圖像輸出,以減少創建進階視覺處理環境所需的機器數量。

OpenGL四路緩衝立體支持
為專業應用程式提供流暢且身臨其境的3D立體體驗。
支持超高解析度桌面
使用最高32K 桌面尺寸的高解析顯示設備,可獲得更多的Mosaic 拓撲功能的選擇。
專業3D立體同步
通過專用連接可強化控制立體效果,並將3D立體顯像硬與Quadro圖形卡直接同步。
軟體支援
Volta 優化軟體
諸如Caffe2,MXNet,CNTK,TensorFlow等深度學習框架顯著加快了訓練時間並提高了多節點訓練效能。 GPU加速庫(如cuDNN,cuBLAS和TensorRT)為深度學習推理和高性能計算(HPC)應用程序提供了更高的性能。
NVIDIA® CUDA® 平行計算平台
本機執行標準編程語言(如C / C ++和Fortran)和API(如OpenCL,OpenACC和Direct Compute),以加速諸如光跡追踪,視訊和圖像處理以及計算流體動力學等技術。
記憶體統一化
單一的無縫49位元虛擬地址空間允許在CPU和GPU記憶體完整分配間進行數據的直接遷移。
NVIDIA® GPUDirect 視訊
GPUDirect視訊透過避免不必要的系統記憶體存取和CPU佔用率,以加速GPU和視訊I/O裝置之間的通信。
NVIDIA Enterprise-Management Tools/企業管理工具
最大限度延長系統的正常運行時間,無縫管理大規模部署,並遠端控制圖形和顯示設備,以實現高效能運營。
BR>
專業應用軟體認證推薦

專業開發人員的Pro VR
針對專業應用程式的開發人員,NVIDIA VRWorks TW SDK能提供簡單的隨插即用頭戴式螢幕(HMD)相容性、低延遲的虛擬 實境渲染技術,以及可在多個GPU之間擴充的效能和同步功能。
- 製造業和建築業在檢視設計的過程中,以VR內容讓設計人員;工程師或客戶見到栩栩如生的作品,讓他們能在獲得充分資訊的情況下做出決定,避免在動工後又大費周章修改設計
- 醫療手術擬真演練
- 複雜系統的人為反映模擬

|
 名人電腦股份有限公司
名人電腦股份有限公司
